



This publication is Open Access under the license indicated. Learn More

ACS Editors' Choice® is a collection designed to feature scientific articles of broad public interest. Read the latest articles
PPO-GPR: A Custom Proximal Policy Optimization Tool for Active Reinforcement LearningClick to copy article linkArticle link copied!
- Etinosa OsaroEtinosa OsaroDepartment of Chemical and Biomolecular Engineering, University of Notre Dame, Notre Dame, Indiana 46556, United StatesMore by Etinosa Osaro
- Yamil J. Colón*Yamil J. Colón*Email: [email protected]Department of Chemical and Biomolecular Engineering, University of Notre Dame, Notre Dame, Indiana 46556, United StatesMore by Yamil J. Colón
ACS Engineering Au
© 2026 The Authors. Published by American Chemical Society. This publication is licensed under
License Summary*
You are free to share (copy and redistribute) this article in any medium or format within the parameters below:

Creative Commons (CC): This is a Creative Commons license.

Attribution (BY): Credit must be given to the creator.

Non-Commercial (NC): Only non-commercial uses of the work are permitted.

No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
Abstract
Efficient data selection is critical in domains where data acquisition is expensive and time-consuming, such as material science. In this work, we introduce a novel active learning framework that integrates proximal policy optimization (PPO) with Gaussian process regression (GPR) to strategically select informative data points and thereby enhance predictive modeling. Leveraging the inherent stability and sample efficiency of PPO, achieved through a clipped surrogate objective, the framework guides data acquisition via a custom-designed Gymnasium environment tailored for GPR. In this environment, the PPO agent dynamically chooses data points based on their potential to improve the GPR’s performance, as measured by the R2 score, while preventing redundancy through an action masking mechanism. We apply the proposed methodology to predict the selectivity of methane (CH4) over higher alkanes in metal–organic frameworks (MOFs), focusing on CuBTC and IRMOF-1. The framework is evaluated using both ternary and quaternary gas mixtures, where the performance of the GPR is assessed through metrics such as R2, mean absolute error (MAE), and root mean squared error (RMSE). Across CuBTC and IRMOF-1 in ternary and quaternary hydrocarbon mixtures, PPO-guided acquisition achieves 77–86% data savings relative to full GCMC grids, typically querying only ∼14–23% of the candidate pool while the clipped-update PPO policy converges stably by focusing selections in the pressure–temperature–composition regions where selectivity changes most rapidly. This work shows the potential of combining advanced reinforcement learning techniques with regression models to accelerate material discovery and optimize gas separation processes.
This publication is licensed under
License Summary*
You are free to share(copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
License Summary*
You are free to share(copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
License Summary*
You are free to share(copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
License Summary*
You are free to share(copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
License Summary*
You are free to share(copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
Special Issue
Published as part of ACS Engineering Au special issue “AI and Machine Learning in Chemical Engineering: Breakthroughs and Applications”.
1. Introduction
2. Background
2.1. Reinforcement Learning: Value and Policy Functions
2.1.1. Value Functions
2.1.2. Policy Functions
2.1.3. Actor-Critic Methods
2.1.4. Q-Learning and the Bellman Equation
2.1.5. Proximal Policy Optimization (PPO)
2.1.5.1. Value Function Approximation
2.1.5.2. Generalized Advantage Estimation (GAE)
2.1.5.3. Entropy Regularization
| aspect | value-based methods | policy-based methods |
|---|---|---|
| primary focus | estimating value functions (V (s), Q(s, a)) | directly learning the policy (π(a|s)) |
| policy derivation | indirectly derived by selecting actions with highest values | explicitly learned and optimized |
| action space | best for discrete or small action spaces | suited for continuous or large action spaces |
| exploration | relies on exploration strategies (e.g., ε-greedy) | can incorporate stochastic policies |
| sample efficiency | generally, more sample-efficient | typically requires more samples |
| common algorithms | Q-Learning, DQN | REINFORCE, (59−61) PPO, A3C, Actor-Critic |
| use cases | games with discrete actions (e.g., Atari) | robotics, control tasks with continuous actions |
3. Methods
3.1. Proximal Policy Optimization with Custom Gaussian Process Regression Environment
3.1.1. Environment Design
3.1.2. State Representation (st)
Availability Vector: A binary vector indicating the availability of each data point in the test set (1 for available, 0 for selected).
Performance Metrics: Current performance metrics of the GPmodel, specifically the R2 score.
Selection History: A history of selected data points up to the current step, providing context for the agent’s decision-making process.
3.1.3. Action Space (A)
3.1.4. Reward Function (rt)
3.2. Termination Conditions
Target Performance: The GPModel achieves or exceeds a target R2.
Exhausted Data Pool: All data points in the test set have been selected.
Maximum Steps: A predefined maximum number of steps is reached, preventing excessively long training episodes.
3.3. Gaussian Process Regression Model (GPModel)
3.4. Grand Canonical Monte Carlo
4. Use Cases: Ternary and Quaternary Selectivity of CH4 over Higher Alkanes in MOFs
4.1. Feature Engineering
Pressure (X1): Measured in bar, ranging from 10–4 to 100 bar. Logarithmic transformation was applied to this feature to stabilize.
Temperature (X2): Ranging from 200 to 400 K. Normalized using mean and standard deviation to ensure numerical stability and consistent scaling.
Mole Fractions (X4, X5, X6(for ternary)): Representing the mole fractions of ethane (C2H6), propane (C3H8), and butane (C4H10, for ternary) respectively.
4.2. Model Initialization and Training
4.3. Model Evaluation
4.4. AL Framework Implementation
4.4.1. Initialization
| 1. | GPModel Training: An initial GPmodel is trained using prior data, establishing a baseline for performance. | ||||
| 2. | PPO Agent Setup: The PPO agent is initialized with the specified policy and value networks, configured with the defined hyperparameters to facilitate effective learning. | ||||
| 3. | Environment Configuration: The GPR_Env environment is set up with all data points available for selection, providing a comprehensive pool from which the agent can draw. | ||||
4.4.2. AL Loop
| 1. | State Observation: At each step, the agent observes the current state st, which includes available data points and the current performance of the GPmodel. | ||||
| 2. | Action Selection: Based on the observed state, the agent selects an action at, corresponding to the index of a specific data point in the test set. | ||||
| 3. | Environment Update: The selected data point is incorporated into the GPmodel’s training set, and the model is retrained to incorporate the latest information. | ||||
| 4. | Reward Assignment: The agent receives a reward rt based on the improvement in the GPModel’s R2 score, incentivizing selections that enhance predictive performance. | ||||
| 5. | Policy and Value Function Update: Using the PPO algorithm, the agent updates its policy and value function parameters to maximize the expected cumulative rewards, refining its data selection strategy over time. | ||||
4.4.3. Termination
4.5. Training and Evaluation Scripts
4.5.1. Training Script (train.py)
4.5.2. Evaluation Script (evaluate.py)
4.5.3. Exporting Final Data set (export_prior_from_idx.py)
4.6. Data Management and Preprocessing
4.6.1. Normalization and Transformation
Pressure (X1): Logarithmic transformation followed by normalization. This transformation stabilizes variance and captures relationships between pressure and selectivity.
Temperature (X2): Normalized using mean and standard deviation to center the data and scale it to unit variance.
Mole Fractions (X4, X5): Normalized to have zero mean and unit variance, ensuring that all features contribute equally to the model’s predictions.
Selectivity (y): Log-transformed and normalized to align with the input features’ scaling and to facilitate the GPModel’s ability to capture nonlinear relationships.
4.6.2. Data Splitting
Prior Data (Prior.csv): This initial training set contains data points as described in Section 4.2, ensuring broad coverage of adsorption conditions and providing the GPModel with diverse training samples.
Test Data (Test.csv): Serving as the pool for AL, this subset contains data points available for the PPO agent to select, enabling the agent to iteratively enhance the GPModel’s performance.
Unlabeled Data (Unlabeled.csv): This subset is used for final prediction assessments without known selectivity values, allowing for an unbiased evaluation of the GPModel’s generalization capabilities.
4.7. Model Training and Updating
4.8. Hyperparameter Configuration
4.8.1. PPO Tunable Hyperparameters
4.8.2. GPModel Hyperparameters
Kernel Parameters: Length scales and variances for the composite Rational Quadratic and Matern kernels. These parameters are crucial for capturing nonlinear and multiscale relationships inherent in the data.
Noise Variance: Represents observation noise in the GPModel, accounting for measurement uncertainties and ensuring robust predictions.
4.8.3. Environment Parameters
Batch Size: Number of data points added to the GPModel (GPModel) at each step (set to 1 for granular selection). This fine-grained selection promotes targeted improvements in the model.
Maximum Steps: Determined based on the total number of available data points (e.g., 100 steps). This parameter prevents excessively long training episodes, balancing thoroughness with computational efficiency.
5. Results
5.1. Performance on Ternary Mixtures
| data set | R2 | MAE | RMSE |
|---|---|---|---|
| CuBTC testing data set (ternary mixture) | 0.980 | 0.002 | 0.010 |
| CuBTC unlabeled data set (ternary mixture) | 0.967 | 0.004 | 0.013 |
| IRMOF-1 testing data set (ternary mixture) | 0.983 | 0.002 | 0.011 |
| IRMOF-1 unlabeled data set (ternary mixture) | 0.840 | 0.007 | 0.029 |
These results are for selectivity of CH4 over C2H6, and C3H8 in the MOFs.
Figure 1
Figure 1. Overlaid distributions of the full design pool (“All”, blue) versus PPO–GPR selections (“Selected”, orange) for CuBTC under the ternary CH4/C2H6/C3H8 case.
Figure 2
Figure 2. RMSE heatmaps for CuBTC (ternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin (labels atop each panel). Color encodes RMSE between model predictions and true selectivity.
Figure 3
Figure 3. Overlaid distributions of the full design pool (“All”, blue) versus PPO–GPR selections (“Selected”, orange) for IRMOF-1 under the ternary CH4/C2H6/C3H8 case.
Figure 4
Figure 4. RMSE heatmaps for IRMOF-1 (ternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin.
Figure 5
Figure 5. Adsorption selectivity isotherms in CuBTC comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6 and C3H8.
Figure 6
Figure 6. Adsorption selectivity isotherms in IRMOF-1 comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6 and C3H8.
5.2. Performance on Quaternary Mixtures
| data set | R2 | MAE | RMSE |
|---|---|---|---|
| CuBTC testing data set (quaternary mixture) | 0.981 | 0.002 | 0.009 |
| CuBTC unlabeled data set (quaternary mixture) | 0.956 | 0.004 | 0.013 |
| IRMOF-1 testing data set (quaternary mixture) | 0.980 | 0.002 | 0.010 |
| IRMOF-1 unlabeled data set (quaternary mixture) | 0.912 | 0.007 | 0.021 |
These results are for selectivity of CH4 over C2H6, C3H8 and C4H10 in the MOFs.
Figure 7
Figure 7. CuBTC, quaternary CH4/C2H6/C3H8/C4H10. Overlaid histograms of the design pool (“All”, blue) and PPO–GPR selections (“Selected”, orange).
Figure 8
Figure 8. RMSE heatmaps for CuBTC (quaternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin of C2H6/C3H8/C4H10.
Figure 9
Figure 9. IRMOF-1, quaternary CH4/C2H6/C3H8/C4H10. Overlaid histograms of the design pool (“All”, blue) and PPO–GPR selections (“Selected”, orange)
Figure 10
Figure 10. RMSE heatmaps for IRMOF-1 (quaternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin of C2H6/C3H8/C4H10.
Figure 11
Figure 11. Adsorption selectivity isotherms in CuBTC comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6, C3H8 and C4H10.
Figure 12
Figure 12. Adsorption selectivity isotherms in IRMOF-1 comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6, C3H8 and C4H10.
| cases | % data saving with respect to full GCMC |
|---|---|
| CuBTC (ternary mixture) | 86 |
| IRMOF-1(ternary mixture) | 81 |
| CuBTC (quaternary mixture) | 82 |
| IRMOF-1 (quaternary mixture) | 77 |
| CuBTC (ternary mixture) | 86 |
6. Conclusion
Data Availability
All codes and data can be found via GitHub here: https://github.com/theOsaroJ/PPO_GPR
Supporting Information
The Supporting Information is available free of charge at https://pubs.acs.org/doi/10.1021/acsengineeringau.5c00122.
Mixture adsorption isotherms for CuBTC and IRMOF-1 under ternary and quaternary conditions (Figures S1–S4); Gaussian process kernel testing and comparison (RQ, Matérn, and composite RQ+Matérn) with performance metrics (Table S1); log-scale sampling/distribution plots comparing the full design pool versus PPO–GPR-selected prior for CuBTC and IRMOF-1, ternary and quaternary cases (Figures S5–S8); R2 heatmaps over pressure–temperature grids for CuBTC and IRMOF-1, ternary and quaternary cases (Figures S9–S12) (PDF)
Terms & Conditions
Most electronic Supporting Information files are available without a subscription to ACS Web Editions. Such files may be downloaded by article for research use (if there is a public use license linked to the relevant article, that license may permit other uses). Permission may be obtained from ACS for other uses through requests via the RightsLink permission system: http://pubs.acs.org/page/copyright/permissions.html.
Author Information
- Yamil J. Colón - Department of Chemical and Biomolecular Engineering, University of Notre Dame, Notre Dame, Indiana 46556, United States;
 https://orcid.org/0000-0001-5316-9692;
https://orcid.org/0000-0001-5316-9692;
- Etinosa Osaro - Department of Chemical and Biomolecular Engineering, University of Notre Dame, Notre Dame, Indiana 46556, United States;https://orcid.org/0000-0003-2744-339X
Acknowledgments
E.O. would like to thank the Lucy Family Institute for Data and Society, and The Patrick and Jana Eilers Graduate Student Fellowship for Energy Related Research at the University of Notre Dame. Y.J.C. gratefully acknowledge NSF CAREER Award No. CBET-2143346 and NSF Award No. CBET-2347040. The authors also thank the Center for Research Computing at the University of Notre Dame for computational resources.
References
This article references 72 other publications.
- 1Ji, Z.; Wang, H.; Canossa, S.; Wuttke, S.; Yaghi, O. M. Pore Chemistry of Metal–Organic Frameworks. Adv. Funct. Mater. 2020, 30, 2000238 DOI: 10.1002/adfm.202000238Google ScholarThere is no corresponding record for this reference.
- 2Furukawa, H.; Cordova, K. E.; O’Keeffe, M.; Yaghi, O. M. The Chemistry and Applications of Metal-Organic Frameworks. Science 2013, 341, 1230444 DOI: 10.1126/science.1230444Google ScholarThere is no corresponding record for this reference.
- 3Kaskel, S. Progress in Advanced Characterization of MOFs. In The Chemistry of Metal-Organic Frameworks: Synthesis, Characterization, and Applications; Wiley, 2016; pp 575– 822.Google ScholarThere is no corresponding record for this reference.
- 4James, S. L. Metal-organic frameworks. Chem. Soc. Rev. 2003, 32, 276, DOI: 10.1039/b200393gGoogle ScholarThere is no corresponding record for this reference.
- 5Jones, C. W. Metal-Organic Frameworks and Covalent Organic Frameworks: Emerging Advances and Applications. JACS Au 2022, 2, 1504– 1505, DOI: 10.1021/jacsau.2c00376Google ScholarThere is no corresponding record for this reference.
- 6Langmi, H. W.; Ren, J.; North, B.; Mathe, M.; Bessarabov, D. Hydrogen storage in metal-organic frameworks: A review. Electrochim. Acta 2014, 128, 368– 392, DOI: 10.1016/j.electacta.2013.10.190Google ScholarThere is no corresponding record for this reference.
- 7Baumann, A. E.; Burns, D. A.; Liu, B.; Thoi, V. S. Metal-organic framework functionalization and design strategies for advanced electrochemical energy storage devices. Commun. Chem. 2019, 2, 1– 14, DOI: 10.1038/s42004-019-0184-6Google ScholarThere is no corresponding record for this reference.
- 8Mao, H.; Tang, J.; Day, G. S. A scalable solid-state nanoporous network with atomic-level interaction design for carbon dioxide capture. Sci. Adv. 2022, 8, abo6849 DOI: 10.1126/sciadv.abo6849Google ScholarThere is no corresponding record for this reference.
- 9Wang, L.; Huang, H.; Zhang, X. Designed metal-organic frameworks with potential for multi-component hydrocarbon separation. Coord. Chem. Rev. 2023, 484, 215111 DOI: 10.1016/j.ccr.2023.215111Google ScholarThere is no corresponding record for this reference.
- 10Zhao, G.; Brabson, L. M.; Chheda, S. CoRE MOF DB: A curated experimental metal-organic framework database with machine-learned properties for integrated material-process screening. Matter 2025, 8, 102140 DOI: 10.1016/j.matt.2025.102140Google ScholarThere is no corresponding record for this reference.
- 11Chung, Y. G.; Haldoupis, E.; Bucior, B. J. Advances, Updates, and Analytics for the Computation-Ready, Experimental Metal–Organic Framework Database: CoRE MOF 2019. J. Chem. Eng. Data 2019, 64, 5985– 5998, DOI: 10.1021/acs.jced.9b00835Google ScholarThere is no corresponding record for this reference.
- 12Colón, Y. J.; Snurr, R. Q. High-throughput computational screening of metal-organic frameworks. Chem. Soc. Rev. 2014, 43, 5735– 5749, DOI: 10.1039/C4CS00070FGoogle ScholarThere is no corresponding record for this reference.
- 13Osaro, E.; Colón, Y. J. Intelligent screening of porous materials: A review of active-learning approaches in MOF research. Chem. Phys. Rev. 2025, 6, 041307 DOI: 10.1063/5.0295283Google ScholarThere is no corresponding record for this reference.
- 14Wang, Z.; Zhou, T.; Sundmacher, K. Interpretable machine learning for accelerating the discovery of metal-organic frameworks for ethane/ethylene separation. Chem. Eng. J. 2022, 444, 136651 DOI: 10.1016/j.cej.2022.136651Google ScholarThere is no corresponding record for this reference.
- 15Lookman, T.; Balachandran, P. V.; Xue, D.; Yuan, R. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. NPJ. Comput. Mater. 2019, 5, 21 DOI: 10.1038/s41524-019-0153-8Google ScholarThere is no corresponding record for this reference.
- 16Cohn, D. A.; Ghahramani, Z.; Jordan, M. I. Active Learning with Statistical Models. J. Artif. Intell. Res. 1996, 4, 129– 145, DOI: 10.1613/jair.295Google ScholarThere is no corresponding record for this reference.
- 17Gubaev, K.; Podryabinkin, E. V.; Shapeev, A. V. Machine learning of molecular properties: Locality and active learning. J. Chem. Phys. 2018, 148, 241727 DOI: 10.1063/1.5005095Google ScholarThere is no corresponding record for this reference.
- 18Ren, P.; Xiao, Y.; Chang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2022, 54, 1– 40, DOI: 10.1145/3472291Google ScholarThere is no corresponding record for this reference.
- 19Osaro, E.; Mukherjee, K.; Colón, Y. J. Active Learning for Adsorption Simulations: Evaluation, Criteria Analysis, and Recommendations for Metal–Organic Frameworks. Ind. Eng. Chem. Res. 2023, 62, 13009– 13024, DOI: 10.1021/acs.iecr.3c01589Google ScholarThere is no corresponding record for this reference.
- 20Mukherjee, K.; Osaro, E.; Colón, Y. J. Active learning for efficient navigation of multi-component gas adsorption landscapes in a MOF. Digital Discovery 2023, 2, 1506– 1521, DOI: 10.1039/D3DD00106GGoogle ScholarThere is no corresponding record for this reference.
- 21Osaro, E.; Fajardo-Rojas, F.; Cooper, G. M.; Gómez-Gualdrón, D.; Colón, Y. J. Active learning of alchemical adsorption simulations; towards a universal adsorption model. Chem. Sci. 2024, 15, 17671– 17684, DOI: 10.1039/D4SC02156HGoogle ScholarThere is no corresponding record for this reference.
- 22Osaro, E.; LaCapra, M.; Colón, Y. J. Harmonizing Adsorption and Diffusion in Active Learning Campaigns of Gas Separations in a MOF. J. Phys. Chem. C 2025, 129, 9877– 9891, DOI: 10.1021/acs.jpcc.5c00922Google ScholarThere is no corresponding record for this reference.
- 23Osaro, E.; Bakare, A.; Colón, Y. J. Multi-method material selection for adsorption using Bayesian approaches. Commun. Mater. 2025, 6, 215, DOI: 10.1038/s43246-025-00933-wGoogle ScholarThere is no corresponding record for this reference.
- 24Gantzler, N.; Deshwal, A.; Doppa, J. R.; Simon, C. M. Multi-fidelity Bayesian optimization of covalent organic frameworks for xenon/krypton separations. Digital Discovery 2023, 2, 1937– 1956, DOI: 10.1039/D3DD00117BGoogle ScholarThere is no corresponding record for this reference.
- 25He, G.-F.; Zhang, P.; Yin, Z.-Y. Active learning inspired multi-fidelity probabilistic modelling of geomaterial property. Comput. Methods Appl. Mech. Eng. 2024, 432, 117373 DOI: 10.1016/j.cma.2024.117373Google ScholarThere is no corresponding record for this reference.
- 26Hernandez-Garcia, A.; Saxena, N.; Jain, M.; Liu, C.-H.; Bengio, Y. Multi-Fidelity Active Learning with GFlowNets. 2024.Google ScholarThere is no corresponding record for this reference.
- 27Wang, A.; Liang, H.; McDannald, A.; Takeuchi, I.; Kusne, A. G. Benchmarking active learning strategies for materials optimization and discovery. Oxford Open Mater. Sci. 2022, 2, itac006 DOI: 10.1093/oxfmat/itac006Google ScholarThere is no corresponding record for this reference.
- 28Kusne, A. G.; Yu, H.; Wu, C. On-the-fly closed-loop materials discovery via Bayesian active learning. Nat. Commun. 2020, 11, 5966 DOI: 10.1038/s41467-020-19597-wGoogle ScholarThere is no corresponding record for this reference.
- 29Deringer, V. L.; Bartók, A. P.; Bernstein, N. Gaussian Process Regression for Materials and Molecules. Chem. Rev. 2021, 121, 10073– 10141, DOI: 10.1021/acs.chemrev.1c00022Google ScholarThere is no corresponding record for this reference.
- 30Rasmussen, C. E. Gaussian Processes in machine learning. In Lecture Notes in Computer Science, Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer, 2004; Vol. 3176, pp 63– 71 DOI: 10.1007/978-3-540-28650-9_4 .Google ScholarThere is no corresponding record for this reference.
- 31Rasmussen, C. E.; Williams, C. K. I. Gaussian Processes for Machine Learning; The MIT Press, 2005 DOI: 10.7551/mitpress/3206.001.0001 .Google ScholarThere is no corresponding record for this reference.
- 32Hensman, J.; Fusi, N.; Lawrence, N. D. Gaussian Processes for Big Data 2013 https://arxiv.org/pdf/1309.6835.Google ScholarThere is no corresponding record for this reference.
- 33Li, Y. Deep Reinforcement Learning: An Overview 2017 https://arxiv.org/abs/1701.07274.Google ScholarThere is no corresponding record for this reference.
- 34Sui, F.; Guo, R.; Zhang, Z.; Gu, G. X.; Lin, L. Deep Reinforcement Learning for Digital Materials Design. ACS Mater. Lett. 2021, 3, 1433– 1439, DOI: 10.1021/acsmaterialslett.1c00390Google ScholarThere is no corresponding record for this reference.
- 35Sutton, R. S. Introduction: The Challenge of Reinforcement Learning. In Reinforcement Learning; Springer US: Boston, MA, 1992; pp 1– 3 DOI: 10.1007/978-1-4615-3618-5_1 .Google ScholarThere is no corresponding record for this reference.
- 36Kaelbling, L. P.; Littman, M. L.; Moore, A. W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237– 285, DOI: 10.1613/jair.301Google ScholarThere is no corresponding record for this reference.
- 37Peters, M.; Ketter, W.; Saar-Tsechansky, M.; Collins, J. A reinforcement learning approach to autonomous decision-making in smart electricity markets. Mach. Learn. 2013, 92, 5– 39, DOI: 10.1007/s10994-013-5340-0Google ScholarThere is no corresponding record for this reference.
- 38Osaro, E.; Colón, Y. J. Optimizing the prediction of adsorption in metal–organic frameworks leveraging Q-learning. AIChE J. 2024, 70, 18611 DOI: 10.1002/aic.18611Google ScholarThere is no corresponding record for this reference.
- 39Park, H.; Majumdar, S.; Zhang, X.; Kim, J.; Smit, B. Inverse design of metal–organic frameworks for direct air capture of CO 2 via deep reinforcement learning. Digital Discovery 2024, 3, 728, DOI: 10.1039/D4DD00010BGoogle ScholarThere is no corresponding record for this reference.
- 40Zhuang, Z.; Lei, K.; Liu, J.; Wang, D.; Guo, Y. Behavior Proximal Policy Optimization. 2023.Google ScholarThere is no corresponding record for this reference.
- 41Gu, Y.; Cheng, Y.; Chen, C. L. P.; Wang, X. Proximal Policy Optimization With Policy Feedback. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4600– 4610, DOI: 10.1109/TSMC.2021.3098451Google ScholarThere is no corresponding record for this reference.
- 42Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2017.Google ScholarThere is no corresponding record for this reference.
- 43Kostrikov, I.; Nair, A.; Levine, S. Offline Reinforcement Learning with Implicit Q-Learning 2021 https://arxiv.org/abs/2110.06169.Google ScholarThere is no corresponding record for this reference.
- 44Tan, F.; Yan, P.; Guan, X. Deep Reinforcement Learning: From Q-Learning to Deep Q-Learning. In Neural Information Processing; Springer, 2017; pp 475– 483 DOI: 10.1007/978-3-319-70093-9_50 .Google ScholarThere is no corresponding record for this reference.
- 45Jang, B.; Kim, M.; Harerimana, G.; Kim, J. W. Q-Learning Algorithms: A Comprehensive Classification and Applications. IEEE Access 2019, 7, 133653– 133667, DOI: 10.1109/ACCESS.2019.2941229Google ScholarThere is no corresponding record for this reference.
- 46Clifton, J.; Laber, E. Q-Learning: Theory and Applications. Annu. Rev. Stat. Appl. 2020, 7, 279– 301, DOI: 10.1146/annurev-statistics-031219-041220Google ScholarThere is no corresponding record for this reference.
- 47Watkins, C. J. C. H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279– 292, DOI: 10.1007/BF00992698Google ScholarThere is no corresponding record for this reference.
- 48Li, S. E. Deep Reinforcement Learning. In Reinforcement Learning for Sequential Decision and Optimal Control; Springer Nature Singapore: Singapore, 2023; pp 365– 402 DOI: 10.1007/978-981-19-7784-8_10 .Google ScholarThere is no corresponding record for this reference.
- 49Sumiea, E. H.; Abdulkadir, S. J.; Alhussian, H. S. Deep deterministic policy gradient algorithm: A systematic review. Heliyon 2024, 10, e30697 DOI: 10.1016/j.heliyon.2024.e30697Google ScholarThere is no corresponding record for this reference.
- 50Li, S.; Wu, Y.; Cui, X. Robust Multi-Agent Reinforcement Learning via Minimax Deep Deterministic Policy Gradient. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4213– 4220, DOI: 10.1609/aaai.v33i01.33014213Google ScholarThere is no corresponding record for this reference.
- 51Tan, H. Reinforcement Learning with Deep Deterministic Policy Gradient. In 2021 International Conference on Artificial Intelligence, Big Data and Algorithms (CAIBDA); IEEE, 2021; pp 82– 85 DOI: 10.1109/CAIBDA53561.2021.00025 .Google ScholarThere is no corresponding record for this reference.
- 52Zhang, J.; Zhang, Z.; Han, S.; Lü, S. Proximal policy optimization via enhanced exploration efficiency. Inf. Sci. 2022, 609, 750– 765, DOI: 10.1016/j.ins.2022.07.111Google ScholarThere is no corresponding record for this reference.
- 53Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms 2017 https://arxiv.org/abs/1707.06347.Google ScholarThere is no corresponding record for this reference.
- 54Zhong, C.; Lu, Z.; Gursoy, M. C.; Velipasalar, S. A Deep Actor-Critic Reinforcement Learning Framework for Dynamic Multichannel Access. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1125– 1139, DOI: 10.1109/TCCN.2019.2952909Google ScholarThere is no corresponding record for this reference.
- 55Gruslys, A.; Dabney, W.; Azar, M. G. The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning 2017 https://arxiv.org/abs/1704.04651.Google ScholarThere is no corresponding record for this reference.
- 56Chen, R.; Goldberg, J. H. Actor-critic reinforcement learning in the songbird. Curr. Opin. Neurobiol. 2020, 65, 1– 9, DOI: 10.1016/j.conb.2020.08.005Google ScholarThere is no corresponding record for this reference.
- 57Han, M.; Zhang, L.; Wang, J.; Pan, W. Actor-Critic Reinforcement Learning for Control With Stability Guarantee. IEEE Robot. Autom. Lett. 2020, 5, 6217– 6224, DOI: 10.1109/LRA.2020.3011351Google ScholarThere is no corresponding record for this reference.
- 58Grondman, I.; Busoniu, L.; Lopes, G. A. D.; Babuska, R. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients. IEEE Trans. Syst, Man, Cybern. 2012, 42, 1291– 1307, DOI: 10.1109/TSMCC.2012.2218595Google ScholarThere is no corresponding record for this reference.
- 59WILLIAMS, R. J.; PENG, J. Function Optimization using Connectionist Reinforcement Learning Algorithms. Connect. Sci. 1991, 3, 241– 268, DOI: 10.1080/09540099108946587Google ScholarThere is no corresponding record for this reference.
- 60Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229– 256Google ScholarThere is no corresponding record for this reference.
- 61Zhang, J.; Kim, J.; O’Donoghue, B.; Boyd, S. Sample Efficient Reinforcement Learning with REINFORCE. Proc. AAAI Conf. Artif. Intell. 2021, 35, 10887– 10895, DOI: 10.1609/aaai.v35i12.17300Google ScholarThere is no corresponding record for this reference.
- 62Brockman, G.; Cheung, V.; Pettersson, L. OpenAI Gym 2016 https://arxiv.org/abs/1606.01540.Google ScholarThere is no corresponding record for this reference.
- 63Towers, M.; Kwiatkowski, A.; Terry, J. Gymnasium: A Standard Interface for Reinforcement Learning Environments 2024 https://arxiv.org/abs/2407.17032.Google ScholarThere is no corresponding record for this reference.
- 64Raffin, A.; Hill, A.; Gleave, A. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1– 8Google ScholarThere is no corresponding record for this reference.
- 65Rappé, A. K.; Casewit, C. J.; Colwell, K. S.; Goddard, W. A.; Skiff, W. M. UFF, a Full Periodic Table Force Field for Molecular Mechanics and Molecular Dynamics Simulations. J. Am. Chem. Soc. 1992, 114, 10024– 10035, DOI: 10.1021/ja00051a040Google ScholarThere is no corresponding record for this reference.
- 66Martin, M. G.; Siepmann, J. I. Transferable Potentials for Phase Equilibria. 1. United-Atom Description of n-Alkanes. J. Phys. Chem. B 1998, 102, 2569– 2577, DOI: 10.1021/jp972543+Google ScholarThere is no corresponding record for this reference.
- 67Dubbeldam, D.; Calero, S.; Ellis, D. E.; Snurr, R. Q. RASPA: Molecular simulation software for adsorption and diffusion in flexible nanoporous materials. Mol. Simul. 2016, 42, 81– 101, DOI: 10.1080/08927022.2015.1010082Google ScholarThere is no corresponding record for this reference.
- 68Gheytanzadeh, M.; Baghban, A.; Habibzadeh, S. Towards estimation of CO2 adsorption on highly porous MOF-based adsorbents using gaussian process regression approach. Sci. Rep. 2021, 11, 15710 DOI: 10.1038/s41598-021-95246-6Google ScholarThere is no corresponding record for this reference.
- 69Dudek, A.; Baranowski, J. Gaussian Processes for Signal Processing and Representation in Control Engineering. Appl. Sci. 2022, 12, 4946 DOI: 10.3390/app12104946Google ScholarThere is no corresponding record for this reference.
- 70Wilson, A.; Adams, R. Gaussian process kernels for pattern discovery and extrapolation. In 30th International Conference on Machine Learning, ICML 2013; ICML, 2013; Vol. 28, pp 2104– 2112.Google ScholarThere is no corresponding record for this reference.
- 71Melkumyan, A.; Ramos, F. Multi-kernel Gaussian Processes , IJCAI International Joint Conference on Artificial Intelligence, 2011; pp 1408– 1413 DOI: 10.5591/978-1-57735-516-8/IJCAI11-238 .Google ScholarThere is no corresponding record for this reference.
- 72Deshwal, A.; Doppa, J. R. Combining Latent Space and Structured Kernels for Bayesian Optimization over Combinatorial Spaces. In Advances in Neural Information Processing Systems; Curran Associates, Inc., 2021; Vol. 10, pp 8185– 8200.Google ScholarThere is no corresponding record for this reference.
Cited By
This article has not yet been cited by other publications.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
ACS Engineering Au
© 2026 The Authors. Published by American Chemical Society. This publication is licensed under
License Summary*
You are free to share (copy and redistribute) this article in any medium or format within the parameters below:
Creative Commons (CC): This is a Creative Commons license.
Attribution (BY): Credit must be given to the creator.
Non-Commercial (NC): Only non-commercial uses of the work are permitted.
No Derivatives (ND): Derivative works may be created for non-commercial purposes, but sharing is prohibited.
*Disclaimer
This summary highlights only some of the key features and terms of the actual license. It is not a license and has no legal value. Carefully review the actual license before using these materials.
Article Views
Altmetric
Citations
Article Views are the COUNTER-compliant sum of full text article downloads since November 2008 (both PDF and HTML) across all institutions and individuals. These metrics are regularly updated to reflect usage leading up to the last few days.
Citations are the number of other articles citing this article, calculated by Crossref and updated daily. Find more information about Crossref citation counts.
The Altmetric Attention Score is a quantitative measure of the attention that a research article has received online. Clicking on the donut icon will load a page at altmetric.com with additional details about the score and the social media presence for the given article. Find more information on the Altmetric Attention Score and how the score is calculated.
Recommended Articles
Abstract
Figure 1

Figure 1. Overlaid distributions of the full design pool (“All”, blue) versus PPO–GPR selections (“Selected”, orange) for CuBTC under the ternary CH4/C2H6/C3H8 case.
Figure 2

Figure 2. RMSE heatmaps for CuBTC (ternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin (labels atop each panel). Color encodes RMSE between model predictions and true selectivity.
Figure 3
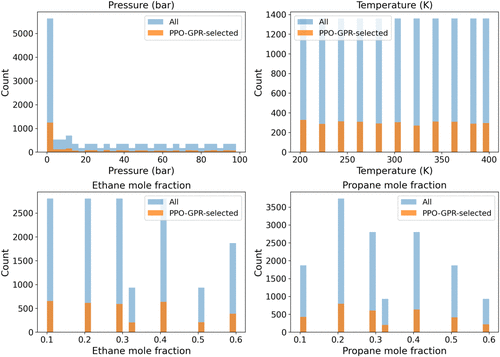
Figure 3. Overlaid distributions of the full design pool (“All”, blue) versus PPO–GPR selections (“Selected”, orange) for IRMOF-1 under the ternary CH4/C2H6/C3H8 case.
Figure 4

Figure 4. RMSE heatmaps for IRMOF-1 (ternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin.
Figure 5

Figure 5. Adsorption selectivity isotherms in CuBTC comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6 and C3H8.
Figure 6
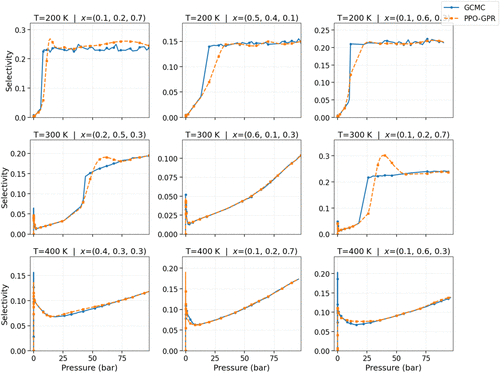
Figure 6. Adsorption selectivity isotherms in IRMOF-1 comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6 and C3H8.
Figure 7

Figure 7. CuBTC, quaternary CH4/C2H6/C3H8/C4H10. Overlaid histograms of the design pool (“All”, blue) and PPO–GPR selections (“Selected”, orange).
Figure 8

Figure 8. RMSE heatmaps for CuBTC (quaternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin of C2H6/C3H8/C4H10.
Figure 9
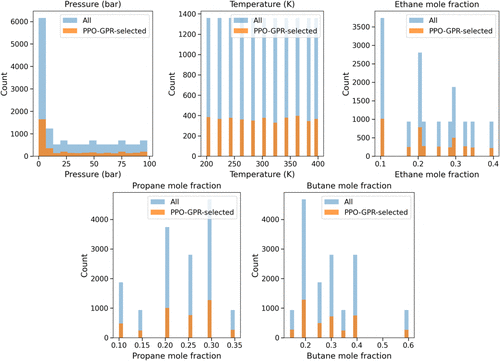
Figure 9. IRMOF-1, quaternary CH4/C2H6/C3H8/C4H10. Overlaid histograms of the design pool (“All”, blue) and PPO–GPR selections (“Selected”, orange)
Figure 10
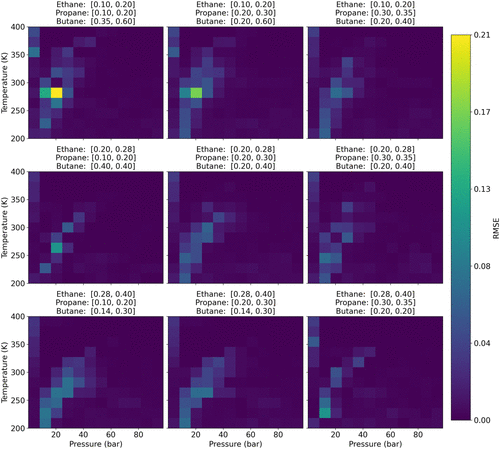
Figure 10. RMSE heatmaps for IRMOF-1 (quaternary). Each panel shows the prediction error over pressure (bar) × temperature (K) for a fixed composition bin of C2H6/C3H8/C4H10.
Figure 11

Figure 11. Adsorption selectivity isotherms in CuBTC comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6, C3H8 and C4H10.
Figure 12
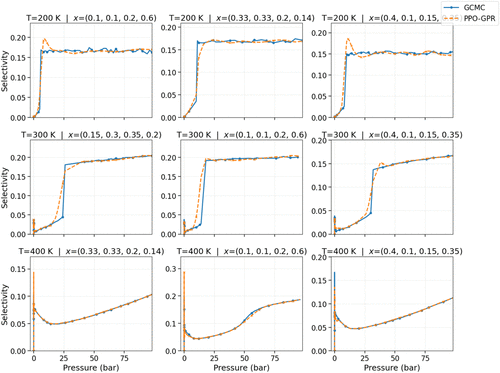
Figure 12. Adsorption selectivity isotherms in IRMOF-1 comparing the PPO-GPR predicted selectivity compared to the ground-truth, across several three temperatures (T) and molar composition (x). “x” is arranged in molar composition of CH4, C2H6, C3H8 and C4H10.
References
This article references 72 other publications.
- 1Ji, Z.; Wang, H.; Canossa, S.; Wuttke, S.; Yaghi, O. M. Pore Chemistry of Metal–Organic Frameworks. Adv. Funct. Mater. 2020, 30, 2000238 DOI: 10.1002/adfm.202000238There is no corresponding record for this reference.
- 2Furukawa, H.; Cordova, K. E.; O’Keeffe, M.; Yaghi, O. M. The Chemistry and Applications of Metal-Organic Frameworks. Science 2013, 341, 1230444 DOI: 10.1126/science.1230444There is no corresponding record for this reference.
- 3Kaskel, S. Progress in Advanced Characterization of MOFs. In The Chemistry of Metal-Organic Frameworks: Synthesis, Characterization, and Applications; Wiley, 2016; pp 575– 822.There is no corresponding record for this reference.
- 4James, S. L. Metal-organic frameworks. Chem. Soc. Rev. 2003, 32, 276, DOI: 10.1039/b200393gThere is no corresponding record for this reference.
- 5Jones, C. W. Metal-Organic Frameworks and Covalent Organic Frameworks: Emerging Advances and Applications. JACS Au 2022, 2, 1504– 1505, DOI: 10.1021/jacsau.2c00376There is no corresponding record for this reference.
- 6Langmi, H. W.; Ren, J.; North, B.; Mathe, M.; Bessarabov, D. Hydrogen storage in metal-organic frameworks: A review. Electrochim. Acta 2014, 128, 368– 392, DOI: 10.1016/j.electacta.2013.10.190There is no corresponding record for this reference.
- 7Baumann, A. E.; Burns, D. A.; Liu, B.; Thoi, V. S. Metal-organic framework functionalization and design strategies for advanced electrochemical energy storage devices. Commun. Chem. 2019, 2, 1– 14, DOI: 10.1038/s42004-019-0184-6There is no corresponding record for this reference.
- 8Mao, H.; Tang, J.; Day, G. S. A scalable solid-state nanoporous network with atomic-level interaction design for carbon dioxide capture. Sci. Adv. 2022, 8, abo6849 DOI: 10.1126/sciadv.abo6849There is no corresponding record for this reference.
- 9Wang, L.; Huang, H.; Zhang, X. Designed metal-organic frameworks with potential for multi-component hydrocarbon separation. Coord. Chem. Rev. 2023, 484, 215111 DOI: 10.1016/j.ccr.2023.215111There is no corresponding record for this reference.
- 10Zhao, G.; Brabson, L. M.; Chheda, S. CoRE MOF DB: A curated experimental metal-organic framework database with machine-learned properties for integrated material-process screening. Matter 2025, 8, 102140 DOI: 10.1016/j.matt.2025.102140There is no corresponding record for this reference.
- 11Chung, Y. G.; Haldoupis, E.; Bucior, B. J. Advances, Updates, and Analytics for the Computation-Ready, Experimental Metal–Organic Framework Database: CoRE MOF 2019. J. Chem. Eng. Data 2019, 64, 5985– 5998, DOI: 10.1021/acs.jced.9b00835There is no corresponding record for this reference.
- 12Colón, Y. J.; Snurr, R. Q. High-throughput computational screening of metal-organic frameworks. Chem. Soc. Rev. 2014, 43, 5735– 5749, DOI: 10.1039/C4CS00070FThere is no corresponding record for this reference.
- 13Osaro, E.; Colón, Y. J. Intelligent screening of porous materials: A review of active-learning approaches in MOF research. Chem. Phys. Rev. 2025, 6, 041307 DOI: 10.1063/5.0295283There is no corresponding record for this reference.
- 14Wang, Z.; Zhou, T.; Sundmacher, K. Interpretable machine learning for accelerating the discovery of metal-organic frameworks for ethane/ethylene separation. Chem. Eng. J. 2022, 444, 136651 DOI: 10.1016/j.cej.2022.136651There is no corresponding record for this reference.
- 15Lookman, T.; Balachandran, P. V.; Xue, D.; Yuan, R. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. NPJ. Comput. Mater. 2019, 5, 21 DOI: 10.1038/s41524-019-0153-8There is no corresponding record for this reference.
- 16Cohn, D. A.; Ghahramani, Z.; Jordan, M. I. Active Learning with Statistical Models. J. Artif. Intell. Res. 1996, 4, 129– 145, DOI: 10.1613/jair.295There is no corresponding record for this reference.
- 17Gubaev, K.; Podryabinkin, E. V.; Shapeev, A. V. Machine learning of molecular properties: Locality and active learning. J. Chem. Phys. 2018, 148, 241727 DOI: 10.1063/1.5005095There is no corresponding record for this reference.
- 18Ren, P.; Xiao, Y.; Chang, X. A Survey of Deep Active Learning. ACM Comput. Surv. 2022, 54, 1– 40, DOI: 10.1145/3472291There is no corresponding record for this reference.
- 19Osaro, E.; Mukherjee, K.; Colón, Y. J. Active Learning for Adsorption Simulations: Evaluation, Criteria Analysis, and Recommendations for Metal–Organic Frameworks. Ind. Eng. Chem. Res. 2023, 62, 13009– 13024, DOI: 10.1021/acs.iecr.3c01589There is no corresponding record for this reference.
- 20Mukherjee, K.; Osaro, E.; Colón, Y. J. Active learning for efficient navigation of multi-component gas adsorption landscapes in a MOF. Digital Discovery 2023, 2, 1506– 1521, DOI: 10.1039/D3DD00106GThere is no corresponding record for this reference.
- 21Osaro, E.; Fajardo-Rojas, F.; Cooper, G. M.; Gómez-Gualdrón, D.; Colón, Y. J. Active learning of alchemical adsorption simulations; towards a universal adsorption model. Chem. Sci. 2024, 15, 17671– 17684, DOI: 10.1039/D4SC02156HThere is no corresponding record for this reference.
- 22Osaro, E.; LaCapra, M.; Colón, Y. J. Harmonizing Adsorption and Diffusion in Active Learning Campaigns of Gas Separations in a MOF. J. Phys. Chem. C 2025, 129, 9877– 9891, DOI: 10.1021/acs.jpcc.5c00922There is no corresponding record for this reference.
- 23Osaro, E.; Bakare, A.; Colón, Y. J. Multi-method material selection for adsorption using Bayesian approaches. Commun. Mater. 2025, 6, 215, DOI: 10.1038/s43246-025-00933-wThere is no corresponding record for this reference.
- 24Gantzler, N.; Deshwal, A.; Doppa, J. R.; Simon, C. M. Multi-fidelity Bayesian optimization of covalent organic frameworks for xenon/krypton separations. Digital Discovery 2023, 2, 1937– 1956, DOI: 10.1039/D3DD00117BThere is no corresponding record for this reference.
- 25He, G.-F.; Zhang, P.; Yin, Z.-Y. Active learning inspired multi-fidelity probabilistic modelling of geomaterial property. Comput. Methods Appl. Mech. Eng. 2024, 432, 117373 DOI: 10.1016/j.cma.2024.117373There is no corresponding record for this reference.
- 26Hernandez-Garcia, A.; Saxena, N.; Jain, M.; Liu, C.-H.; Bengio, Y. Multi-Fidelity Active Learning with GFlowNets. 2024.There is no corresponding record for this reference.
- 27Wang, A.; Liang, H.; McDannald, A.; Takeuchi, I.; Kusne, A. G. Benchmarking active learning strategies for materials optimization and discovery. Oxford Open Mater. Sci. 2022, 2, itac006 DOI: 10.1093/oxfmat/itac006There is no corresponding record for this reference.
- 28Kusne, A. G.; Yu, H.; Wu, C. On-the-fly closed-loop materials discovery via Bayesian active learning. Nat. Commun. 2020, 11, 5966 DOI: 10.1038/s41467-020-19597-wThere is no corresponding record for this reference.
- 29Deringer, V. L.; Bartók, A. P.; Bernstein, N. Gaussian Process Regression for Materials and Molecules. Chem. Rev. 2021, 121, 10073– 10141, DOI: 10.1021/acs.chemrev.1c00022There is no corresponding record for this reference.
- 30Rasmussen, C. E. Gaussian Processes in machine learning. In Lecture Notes in Computer Science, Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer, 2004; Vol. 3176, pp 63– 71 DOI: 10.1007/978-3-540-28650-9_4 .There is no corresponding record for this reference.
- 31Rasmussen, C. E.; Williams, C. K. I. Gaussian Processes for Machine Learning; The MIT Press, 2005 DOI: 10.7551/mitpress/3206.001.0001 .There is no corresponding record for this reference.
- 32Hensman, J.; Fusi, N.; Lawrence, N. D. Gaussian Processes for Big Data 2013 https://arxiv.org/pdf/1309.6835.There is no corresponding record for this reference.
- 33Li, Y. Deep Reinforcement Learning: An Overview 2017 https://arxiv.org/abs/1701.07274.There is no corresponding record for this reference.
- 34Sui, F.; Guo, R.; Zhang, Z.; Gu, G. X.; Lin, L. Deep Reinforcement Learning for Digital Materials Design. ACS Mater. Lett. 2021, 3, 1433– 1439, DOI: 10.1021/acsmaterialslett.1c00390There is no corresponding record for this reference.
- 35Sutton, R. S. Introduction: The Challenge of Reinforcement Learning. In Reinforcement Learning; Springer US: Boston, MA, 1992; pp 1– 3 DOI: 10.1007/978-1-4615-3618-5_1 .There is no corresponding record for this reference.
- 36Kaelbling, L. P.; Littman, M. L.; Moore, A. W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237– 285, DOI: 10.1613/jair.301There is no corresponding record for this reference.
- 37Peters, M.; Ketter, W.; Saar-Tsechansky, M.; Collins, J. A reinforcement learning approach to autonomous decision-making in smart electricity markets. Mach. Learn. 2013, 92, 5– 39, DOI: 10.1007/s10994-013-5340-0There is no corresponding record for this reference.
- 38Osaro, E.; Colón, Y. J. Optimizing the prediction of adsorption in metal–organic frameworks leveraging Q-learning. AIChE J. 2024, 70, 18611 DOI: 10.1002/aic.18611There is no corresponding record for this reference.
- 39Park, H.; Majumdar, S.; Zhang, X.; Kim, J.; Smit, B. Inverse design of metal–organic frameworks for direct air capture of CO 2 via deep reinforcement learning. Digital Discovery 2024, 3, 728, DOI: 10.1039/D4DD00010BThere is no corresponding record for this reference.
- 40Zhuang, Z.; Lei, K.; Liu, J.; Wang, D.; Guo, Y. Behavior Proximal Policy Optimization. 2023.There is no corresponding record for this reference.
- 41Gu, Y.; Cheng, Y.; Chen, C. L. P.; Wang, X. Proximal Policy Optimization With Policy Feedback. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4600– 4610, DOI: 10.1109/TSMC.2021.3098451There is no corresponding record for this reference.
- 42Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. 2017.There is no corresponding record for this reference.
- 43Kostrikov, I.; Nair, A.; Levine, S. Offline Reinforcement Learning with Implicit Q-Learning 2021 https://arxiv.org/abs/2110.06169.There is no corresponding record for this reference.
- 44Tan, F.; Yan, P.; Guan, X. Deep Reinforcement Learning: From Q-Learning to Deep Q-Learning. In Neural Information Processing; Springer, 2017; pp 475– 483 DOI: 10.1007/978-3-319-70093-9_50 .There is no corresponding record for this reference.
- 45Jang, B.; Kim, M.; Harerimana, G.; Kim, J. W. Q-Learning Algorithms: A Comprehensive Classification and Applications. IEEE Access 2019, 7, 133653– 133667, DOI: 10.1109/ACCESS.2019.2941229There is no corresponding record for this reference.
- 46Clifton, J.; Laber, E. Q-Learning: Theory and Applications. Annu. Rev. Stat. Appl. 2020, 7, 279– 301, DOI: 10.1146/annurev-statistics-031219-041220There is no corresponding record for this reference.
- 47Watkins, C. J. C. H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279– 292, DOI: 10.1007/BF00992698There is no corresponding record for this reference.
- 48Li, S. E. Deep Reinforcement Learning. In Reinforcement Learning for Sequential Decision and Optimal Control; Springer Nature Singapore: Singapore, 2023; pp 365– 402 DOI: 10.1007/978-981-19-7784-8_10 .There is no corresponding record for this reference.
- 49Sumiea, E. H.; Abdulkadir, S. J.; Alhussian, H. S. Deep deterministic policy gradient algorithm: A systematic review. Heliyon 2024, 10, e30697 DOI: 10.1016/j.heliyon.2024.e30697There is no corresponding record for this reference.
- 50Li, S.; Wu, Y.; Cui, X. Robust Multi-Agent Reinforcement Learning via Minimax Deep Deterministic Policy Gradient. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4213– 4220, DOI: 10.1609/aaai.v33i01.33014213There is no corresponding record for this reference.
- 51Tan, H. Reinforcement Learning with Deep Deterministic Policy Gradient. In 2021 International Conference on Artificial Intelligence, Big Data and Algorithms (CAIBDA); IEEE, 2021; pp 82– 85 DOI: 10.1109/CAIBDA53561.2021.00025 .There is no corresponding record for this reference.
- 52Zhang, J.; Zhang, Z.; Han, S.; Lü, S. Proximal policy optimization via enhanced exploration efficiency. Inf. Sci. 2022, 609, 750– 765, DOI: 10.1016/j.ins.2022.07.111There is no corresponding record for this reference.
- 53Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms 2017 https://arxiv.org/abs/1707.06347.There is no corresponding record for this reference.
- 54Zhong, C.; Lu, Z.; Gursoy, M. C.; Velipasalar, S. A Deep Actor-Critic Reinforcement Learning Framework for Dynamic Multichannel Access. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1125– 1139, DOI: 10.1109/TCCN.2019.2952909There is no corresponding record for this reference.
- 55Gruslys, A.; Dabney, W.; Azar, M. G. The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning 2017 https://arxiv.org/abs/1704.04651.There is no corresponding record for this reference.
- 56Chen, R.; Goldberg, J. H. Actor-critic reinforcement learning in the songbird. Curr. Opin. Neurobiol. 2020, 65, 1– 9, DOI: 10.1016/j.conb.2020.08.005There is no corresponding record for this reference.
- 57Han, M.; Zhang, L.; Wang, J.; Pan, W. Actor-Critic Reinforcement Learning for Control With Stability Guarantee. IEEE Robot. Autom. Lett. 2020, 5, 6217– 6224, DOI: 10.1109/LRA.2020.3011351There is no corresponding record for this reference.
- 58Grondman, I.; Busoniu, L.; Lopes, G. A. D.; Babuska, R. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients. IEEE Trans. Syst, Man, Cybern. 2012, 42, 1291– 1307, DOI: 10.1109/TSMCC.2012.2218595There is no corresponding record for this reference.
- 59WILLIAMS, R. J.; PENG, J. Function Optimization using Connectionist Reinforcement Learning Algorithms. Connect. Sci. 1991, 3, 241– 268, DOI: 10.1080/09540099108946587There is no corresponding record for this reference.
- 60Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229– 256There is no corresponding record for this reference.
- 61Zhang, J.; Kim, J.; O’Donoghue, B.; Boyd, S. Sample Efficient Reinforcement Learning with REINFORCE. Proc. AAAI Conf. Artif. Intell. 2021, 35, 10887– 10895, DOI: 10.1609/aaai.v35i12.17300There is no corresponding record for this reference.
- 62Brockman, G.; Cheung, V.; Pettersson, L. OpenAI Gym 2016 https://arxiv.org/abs/1606.01540.There is no corresponding record for this reference.
- 63Towers, M.; Kwiatkowski, A.; Terry, J. Gymnasium: A Standard Interface for Reinforcement Learning Environments 2024 https://arxiv.org/abs/2407.17032.There is no corresponding record for this reference.
- 64Raffin, A.; Hill, A.; Gleave, A. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 1– 8There is no corresponding record for this reference.
- 65Rappé, A. K.; Casewit, C. J.; Colwell, K. S.; Goddard, W. A.; Skiff, W. M. UFF, a Full Periodic Table Force Field for Molecular Mechanics and Molecular Dynamics Simulations. J. Am. Chem. Soc. 1992, 114, 10024– 10035, DOI: 10.1021/ja00051a040There is no corresponding record for this reference.
- 66Martin, M. G.; Siepmann, J. I. Transferable Potentials for Phase Equilibria. 1. United-Atom Description of n-Alkanes. J. Phys. Chem. B 1998, 102, 2569– 2577, DOI: 10.1021/jp972543+There is no corresponding record for this reference.
- 67Dubbeldam, D.; Calero, S.; Ellis, D. E.; Snurr, R. Q. RASPA: Molecular simulation software for adsorption and diffusion in flexible nanoporous materials. Mol. Simul. 2016, 42, 81– 101, DOI: 10.1080/08927022.2015.1010082There is no corresponding record for this reference.
- 68Gheytanzadeh, M.; Baghban, A.; Habibzadeh, S. Towards estimation of CO2 adsorption on highly porous MOF-based adsorbents using gaussian process regression approach. Sci. Rep. 2021, 11, 15710 DOI: 10.1038/s41598-021-95246-6There is no corresponding record for this reference.
- 69Dudek, A.; Baranowski, J. Gaussian Processes for Signal Processing and Representation in Control Engineering. Appl. Sci. 2022, 12, 4946 DOI: 10.3390/app12104946There is no corresponding record for this reference.
- 70Wilson, A.; Adams, R. Gaussian process kernels for pattern discovery and extrapolation. In 30th International Conference on Machine Learning, ICML 2013; ICML, 2013; Vol. 28, pp 2104– 2112.There is no corresponding record for this reference.
- 71Melkumyan, A.; Ramos, F. Multi-kernel Gaussian Processes , IJCAI International Joint Conference on Artificial Intelligence, 2011; pp 1408– 1413 DOI: 10.5591/978-1-57735-516-8/IJCAI11-238 .There is no corresponding record for this reference.
- 72Deshwal, A.; Doppa, J. R. Combining Latent Space and Structured Kernels for Bayesian Optimization over Combinatorial Spaces. In Advances in Neural Information Processing Systems; Curran Associates, Inc., 2021; Vol. 10, pp 8185– 8200.There is no corresponding record for this reference.
Supporting Information
Supporting Information
The Supporting Information is available free of charge at https://pubs.acs.org/doi/10.1021/acsengineeringau.5c00122.
Mixture adsorption isotherms for CuBTC and IRMOF-1 under ternary and quaternary conditions (Figures S1–S4); Gaussian process kernel testing and comparison (RQ, Matérn, and composite RQ+Matérn) with performance metrics (Table S1); log-scale sampling/distribution plots comparing the full design pool versus PPO–GPR-selected prior for CuBTC and IRMOF-1, ternary and quaternary cases (Figures S5–S8); R2 heatmaps over pressure–temperature grids for CuBTC and IRMOF-1, ternary and quaternary cases (Figures S9–S12) (PDF)
Terms & Conditions
Most electronic Supporting Information files are available without a subscription to ACS Web Editions. Such files may be downloaded by article for research use (if there is a public use license linked to the relevant article, that license may permit other uses). Permission may be obtained from ACS for other uses through requests via the RightsLink permission system: http://pubs.acs.org/page/copyright/permissions.html.